
Table of Contents
- Introduction to the AI Development Life Cycle
- What is the AI Development Life Cycle?
- Stage 1: Problem Definition and Requirements Gathering
- Stage 2: Data Collection and Preparation
- Stage 3: Data Exploration and Analysis
- Stage 4: Feature Engineering and Selection
- Stage 5: Model Selection
- Stage 6: Model Training
- Stage 7: Model Evaluation
- Stage 8: Model Optimization and Tuning
- Stage 9: Deployment Planning
- Stage 10: Model Deployment
- Stage 11: Continuous Monitoring and Maintenance
- Stage 12: Feedback and Iteration
- Stage 13: Retraining and Model Updates
- Tools and Technologies Used Throughout the AI Development Life Cycle
- Common Challenges in the AI Development Life Cycle
- Best Practices for an Effective AI Development Life Cycle
- Case Study: Real-World Application of the AI Development Life Cycle
- Conclusion and Future Trends in the AI Development Life Cycle
1. Introduction to the AI Development Life Cycle
As someone who has been fascinated by artificial intelligence (AI) and its transformative potential, I’ve come to appreciate the importance of a structured approach to developing AI solutions. This is where the AI Development Life Cycle comes into play. It outlines the stages involved in creating and operationalizing AI systems, ensuring that projects are executed efficiently and effectively. Following a structured life cycle can significantly optimize project outcomes by providing a clear roadmap from problem identification to deployment and maintenance. In this blog, I aim to explore each stage of the AI development process in detail, highlighting its importance and best practices to ensure successful implementation.
also read: Apple Vision Pro: Revolutionizing AR/VR Technology
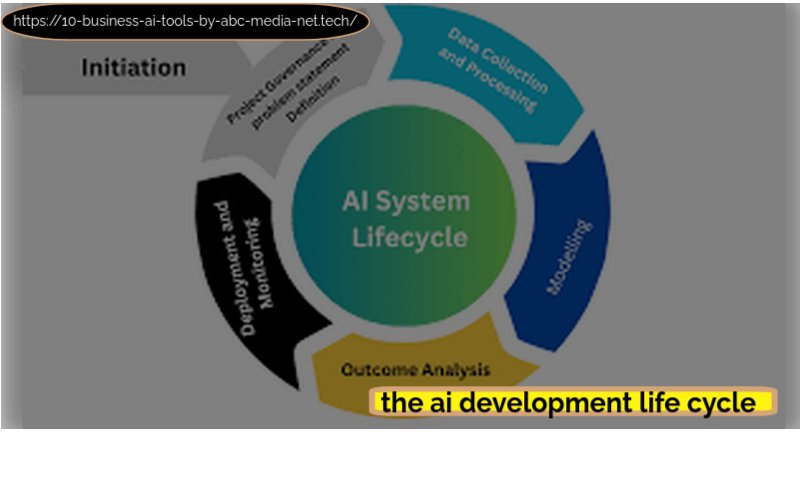
2. What is the AI Development Life Cycle?
The AI Development Life Cycle is a systematic process that guides the development of AI solutions from conception to deployment. Its primary purpose is to provide a framework for structured AI development, ensuring that all necessary steps are taken to create functional and reliable models.
Importance of Structured Development
I believe structured development is essential for several reasons:
- Clarity: It offers clarity on the objectives and requirements of the project.
- Efficiency: By following a defined process, I can avoid common pitfalls and streamline my efforts.
- Quality Assurance: A structured approach allows for thorough testing and validation, leading to higher-quality outcomes.
Comparison with Traditional Software Development Life Cycles
While traditional software development life cycles (SDLC) focus on coding, testing, and deployment, the AI development life cycle incorporates unique requirements specific to AI projects. For instance, data collection and preparation are critical stages in AI development that are not as prominent in conventional software development. Additionally, the iterative nature of model training and evaluation distinguishes the AI life cycle from traditional approaches.
3. Stage 1: Problem Definition and Requirements Gathering
The first stage of the AI development life cycle involves defining the problem and gathering requirements. This step is crucial as it sets the foundation for the entire project.
Importance of Clear Objectives
Identifying clear objectives helps ensure that my AI solution aligns with business goals. Without well-defined objectives, projects can become unfocused, leading to wasted resources and time.
Techniques for Understanding the Problem Domain
To effectively gather business requirements, I find several techniques helpful:
- Stakeholder Interviews: Engaging with stakeholders helps uncover their needs and expectations.
- Surveys and Questionnaires: Collecting feedback through surveys can provide valuable insights into user requirements.
- Workshops: Collaborative workshops can facilitate discussions among stakeholders to clarify objectives.
Questions to Ask Stakeholders
To ensure alignment with business goals, I consider asking stakeholders questions such as:
- What specific problem are we trying to solve?
- What are the desired outcomes of this project?
- Who will be using the AI solution, and what are their needs?
- What constraints or limitations should we consider?
By addressing these questions early on, I can create a solid foundation for my AI project.
4. Stage 2: Data Collection and Preparation
Once I have defined the problem, the next step is data collection and preparation. Data serves as the foundation for any AI model; thus, its quality directly impacts model performance.
Overview of Data Sources
Data can be collected from various sources, including:
- Databases: Internal company databases often contain valuable historical data.
- Public Datasets: Many organizations share datasets that I can leverage for training models.
- Web Scraping: Extracting data from websites can provide additional insights.
- APIs: Many platforms offer APIs that allow me to access their data programmatically.
Importance of Data Quality, Volume, and Diversity

High-quality data is essential for training effective models. Factors I consider include:
- Volume: Sufficient data volume ensures that models can learn patterns effectively.
- Diversity: Diverse datasets help prevent biases in model predictions.
- Quality: Clean, accurate data leads to better model performance.
Key Steps in Data Preparation
Data preparation involves several key steps:
- Data Cleaning: Removing errors or inconsistencies from the dataset. This may involve handling missing values or correcting typos.
- Data Labeling: Annotating data points for supervised learning tasks (e.g., labeling images).
- Data Formatting: Ensuring that data is in a suitable format for analysis (e.g., converting date formats).
5. Stage 3: Data Exploration and Analysis
After preparing the data, it’s time for exploration and analysis. This stage involves gaining insights into the dataset to inform subsequent modeling decisions.
Descriptive Analysis
Descriptive analysis helps me understand trends, patterns, and biases within the dataset. Techniques include:
- Summary Statistics: Calculating mean, median, mode provides an overview of data characteristics.
- Distribution Analysis: Understanding how data points are distributed aids in identifying potential outliers or biases.
Tools for Data Visualization
Data visualization tools play a crucial role in exploratory data analysis (EDA). Some tools I find useful include:
- Matplotlib (Python): A versatile library for creating static visualizations.
- Seaborn (Python): Built on Matplotlib; it simplifies complex visualizations.
- Tableau: A powerful tool for interactive data visualization that allows users like me to create dashboards easily.
Identifying Biases or Gaps
During this stage, it’s important for me to identify any biases or gaps in the dataset that may affect model performance. Techniques include:
- Visual Inspection: Reviewing visualizations can reveal anomalies or imbalances in classes.
- Statistical Tests: Conducting tests helps quantify biases present in the data.
6. Stage 4: Feature Engineering and Selection
Feature engineering is a critical step that involves transforming raw data into meaningful features that improve model performance.
Overview of Feature Engineering
Feature engineering enhances model accuracy by creating new features or modifying existing ones based on domain knowledge. This process often requires creativity and an understanding of both the data and the problem domain.
Common Feature Engineering Techniques
Some common techniques I use include:
- Scaling: Normalizing feature values ensures they contribute equally during training.
- Encoding Categorical Variables: Converting categorical variables into numerical formats (e.g., one-hot encoding).
- Transformations: Applying mathematical transformations (e.g., logarithmic transformations) to improve linearity in relationships between features.
Feature Selection Methods
Feature selection aims to reduce dimensionality while retaining relevant attributes. Techniques I often employ include:
- Filter Methods: Using statistical tests (e.g., ANOVA) to select features based on their relationship with target variables.
- Wrapper Methods: Evaluating subsets of features based on model performance using techniques like recursive feature elimination (RFE).
- Embedded Methods: Performing feature selection during model training (e.g., Lasso regression), which penalizes less important features automatically.
7. Stage 5: Model Selection
With features prepared, it’s time for me to select an appropriate model for my problem.
Criteria for Model Selection
When selecting a model, I consider factors such as:
- Type of Problem: Determine whether it’s a supervised or unsupervised learning task.
- Data Characteristics: Assess whether my data is structured or unstructured.
- Performance Metrics: Identify which metrics will be used to evaluate success (e.g., accuracy vs. recall).
Overview of Common AI Model Types
Several types of models are commonly used in AI development:
- Neural Networks: Suitable for complex problems like image recognition due to their ability to learn hierarchical representations.
- Decision Trees: Useful for classification tasks with clear decision boundaries; they are interpretable but can overfit if not properly managed.
- Clustering Algorithms: Ideal for grouping similar data points without labeled outputs (e.g., K-means clustering).
- Support Vector Machines (SVM): Effective for high-dimensional spaces; they work well with both linear and non-linear decision boundaries.
Pros and Cons of Different Models
Each model type has its advantages and disadvantages based on project requirements:
| Model Type | Pros | Cons |
|---|---|---|
| Neural Networks | High accuracy with complex datasets | Requires significant computational power |
| Decision Trees | Easy interpretation | Prone to overfitting |
| Clustering Algorithms | Useful for exploratory analysis | Sensitive to initial conditions |
| Support Vector Machines | Effective in high-dimensional spaces | Less interpretable than decision trees |
8. Stage 6: Model Training
Once I have selected a model, it must be trained using prepared data.
Overview of Model Training Process
Model training involves exposing my chosen algorithm to training data so it can learn patterns and relationships within that dataset.
Training/Validation Splits
To ensure robust evaluation during training:
- Training Set: Used to fit the model parameters.
- Validation Set: Used to tune hyperparameters and assess performance during training.
- Test Set: Kept separate until final evaluation; it provides an unbiased assessment of how well my model generalizes.
Importance of Hyperparameter Tuning
Hyperparameters significantly influence model performance but must be set before training begins. Common techniques for tuning include:
- Grid Search: Exhaustively searching through combinations of hyperparameters within specified ranges.
- Random Search: Randomly sampling hyperparameter combinations within specified ranges; often more efficient than grid search.
- Bayesian Optimization: An advanced method that uses probabilistic models to find optimal hyperparameters more efficiently than grid search methods.
Common Training Challenges
Training models can present challenges such as overfitting (where models perform well on training data but poorly on unseen data) or underfitting (where models fail to capture underlying trends). Techniques like regularization (L1/L2 regularization) can help mitigate these issues by penalizing overly complex models.
9. Stage 7: Model Evaluation
After training comes evaluation—an essential step in assessing how well my model performs against unseen data.
Evaluation Metrics
Various metrics are used depending on whether I’m dealing with classification or regression tasks:
For Classification:
- Accuracy: The proportion of correct predictions among total predictions made.
- Precision: The proportion of true positive predictions among all positive predictions made by the model.
- Recall: The proportion of true positive predictions among all actual positives; also known as sensitivity.
- F1 Score: The harmonic mean between precision and recall; useful when dealing with imbalanced datasets.
For Regression:
- Mean Absolute Error (MAE): The average absolute difference between predicted values and actual values; provides insight into average error magnitude.
- Mean Squared Error (MSE): The average squared difference between predicted values and actual values; emphasizes larger errors due to squaring differences.
Validation Techniques
To validate my model’s performance effectively:
- Cross-validation: Splitting my dataset into multiple subsets allows me to train multiple models on different splits while validating them against others—this provides a robust estimate of model performance across various scenarios.
2 .Holdout Method: Keeping a portion of my dataset separate from training until final evaluation provides an unbiased assessment of how well my model generalizes!
Importance of Model Interpretability
Understanding how my model makes decisions is crucial—especially in regulated industries like healthcare or finance where accountability matters! Tools like SHAP values or LIME can help explain predictions made by complex models while ensuring ethical considerations are met during evaluation!
10. Stage 8: Model Optimization and Tuning
After evaluating my model’s performance—it’s time for optimization—refining it further based on insights gained during evaluation!
Techniques for Refining Performance
Common optimization techniques include hyperparameter tuning (as discussed earlier), feature selection adjustments if necessary—or even revisiting earlier stages like feature engineering!
Optimization Tools
Several tools exist specifically designed for optimization purposes:1 .Grid Search CV: Automates hyperparameter tuning using cross-validation techniques!
2 .Bayesian Optimization: An advanced method that uses probabilistic models finding optimal hyperparameters more efficiently than grid search methods!
11 .Stage 9: Deployment Planning
Once optimized successfully—planning becomes critical before deploying my model into production environments!
Planning For Production Deployment
Considerations during this phase include:1 .Identifying potential integration challenges with existing systems
2 .Selecting an appropriate deployment environment—whether cloud-based solutions or on-premises setups
Preparing For Scalability
I need to ensure scalability by designing systems capable handling increased loads while maintaining performance levels post-deployment!
12 .Stage 10: Model Deployment
With planning complete—it’s finally time! Deploying an AI model involves integrating it into production systems so it can start making predictions based on real-time input!
Steps For Deployment
Key steps include:1 .Setting up infrastructure required
2 .Integrating APIs if necessary
3 .Monitoring tools should also be established at this stage
Monitoring Tools
Tools such as Grafana or Prometheus allow me track metrics related performance once deployed!
13 .Stage 11: Continuous Monitoring And Maintenance
Post-deployment doesn’t mean “set it & forget it”—continuous monitoring ensures long-term success!
Necessity Of Monitoring Performance
Monitoring allows me detect drift over time—whereby changes occur within input distributions leading potentially inaccurate predictions!
Tools & Techniques
I employ monitoring frameworks like MLflow or DVC which help track metrics over time while detecting anomalies proactively!
14 .Stage 12: Feedback And Iteration
Feedback loops play an essential role! Gathering user/system feedback enables continual improvement throughout lifecycle stages!
Techniques For Gathering Feedback
I consider methods such as surveys among users post-deployment analyzing logs generated by system usage patterns!
15 .Stage 13: Retraining & Model Updates
As new data becomes available—retraining becomes essential! This ensures my models remain relevant adapting changes occurring within environments they operate under!
Best Practices
I establish automated retraining pipelines where possible allowing seamless integration updated versions without significant downtime!
16 .Tools & Technologies Used Throughout The Lifecycle
A plethora tools exist catering various stages—from preprocessing through deployment! Examples include:1 .TensorFlow & PyTorch—popular frameworks widely adopted among practitioners!
2 .Pandas & NumPy—essential libraries aiding preprocessing tasksSelecting appropriate tools depends largely upon complexity involved along team expertise levels!
17 .Common Challenges In The Lifecycle
Typical challenges faced during lifecycle implementation comprise issues surrounding:1 .Data quality concerns leading potential inaccuracies
2 .Computational resource limitations impacting efficiencyOvercoming obstacles requires strategic planning alongside collaboration among teams involved throughout process!
18 .Best Practices For Effective Lifecycle Management
Key practices enhancing overall effectiveness include fostering collaboration among stakeholders while maintaining documentation throughout processes undertaken
19 .Case Study :
Real World Application Of The Life cycle Let’s showcase an example where a company successfully implemented lifecycle framework yielding positive results! For instance, consider Company X—a healthcare startup aiming at predicting patient readmission rates using historical medical records! They followed these steps meticulously resulting improved accuracy rates significantly reducing costs associated hospital stays! Their success story exemplifies importance structured approach towards achieving desired outcomes within competitive landscape today!
20 .Conclusion And Future Trends In The Life cycle
In conclusion—a structured approach remains paramount ensuring successful implementation across diverse applications! Future trends indicate increasing reliance upon automated machine learning techniques alongside explainable ai frameworks becoming more prevalent moving forward!
As technology evolves rapidly—I must adapt accordingly embracing new methodologies enhancing capabilities leveraging power artificial intelligence effectively responsibly! This comprehensive guide covers each stage of the AI Development Life Cycle while incorporating personal reflections on why each aspect matters in real-world applications! If you’re embarking on your own journey into AI development—I hope this serves as a valuable resource guiding you along way!
FAQs
Q1: What is the AI Development Life Cycle?
A1: The AI Development Life Cycle is a systematic process that guides the development of AI solutions from conception to deployment, ensuring that all necessary steps are taken to create functional and reliable models.
Q2: Why is a structured approach important in AI development?
A2: A structured approach provides clarity on objectives, enhances efficiency, and ensures quality assurance throughout the project, ultimately leading to better outcomes.
Q3: What are the main stages of the AI Development Life Cycle?
A3: The main stages include problem definition, data collection, data exploration, feature engineering, model selection, model training, model evaluation, model optimization, deployment planning, model deployment, continuous monitoring, feedback iteration, and retraining.
Q4: How do I gather requirements for an AI project?
A4: Requirements can be gathered through stakeholder interviews, surveys, questionnaires, and collaborative workshops to ensure alignment with business goals.
Q5: What tools are commonly used in the AI development process?
A5: Popular tools include Tensor Flow and PyTorch for model training, Pandas and NumPy for data manipulation, and visualization tools like Matplotlib and Tableau.
Q6: How can I ensure data quality during collection?
A6: Ensuring data quality involves cleaning the data to remove errors or inconsistencies, verifying sources for accuracy, and ensuring sufficient volume and diversity.
Q7: What are some common challenges in the AI development life cycle?
A7: Common challenges include data quality issues, computational resource limitations, model bias, and difficulties in model interpretability.
Q8: How often should I retrain my AI model?
A8: Retraining should occur regularly based on new data availability or when significant changes in input distributions are detected that may affect model performance.
Q9: Why is model interpretability important?
A9: Model interpretability is crucial for understanding how decisions are made by the model, especially in regulated industries where accountability is essential.
Q10: What future trends should I be aware of in AI development?
A10: Future trends include increased reliance on automated machine learning (AutoML), explainable AI (XAI), and advancements in ethical considerations surrounding AI usage.






1 thought on “The AI Development Life Cycle: A Comprehensive Guide”